Active learning¶
Active learning is a training regime, where the goal is to fit a model on the most discriminative samples. It is usually applied in situations where a limited amount of labeled data is available. In such a case, a human might be asked to annotate a sample. Doing this is expensive, so it's important to ask for labels for the most samples that will have the most impact.
Online active learning is active learning done in a streaming fashion. Every time a prediction is made, an active learning strategy decides whether a label should be asked for or not. In case the strategy decides a yes, then the system could ask for a human to intervene. This is well summarized in the following schema from Online Active Learning Methods for Fast Label-Efficient Spam Filtering.
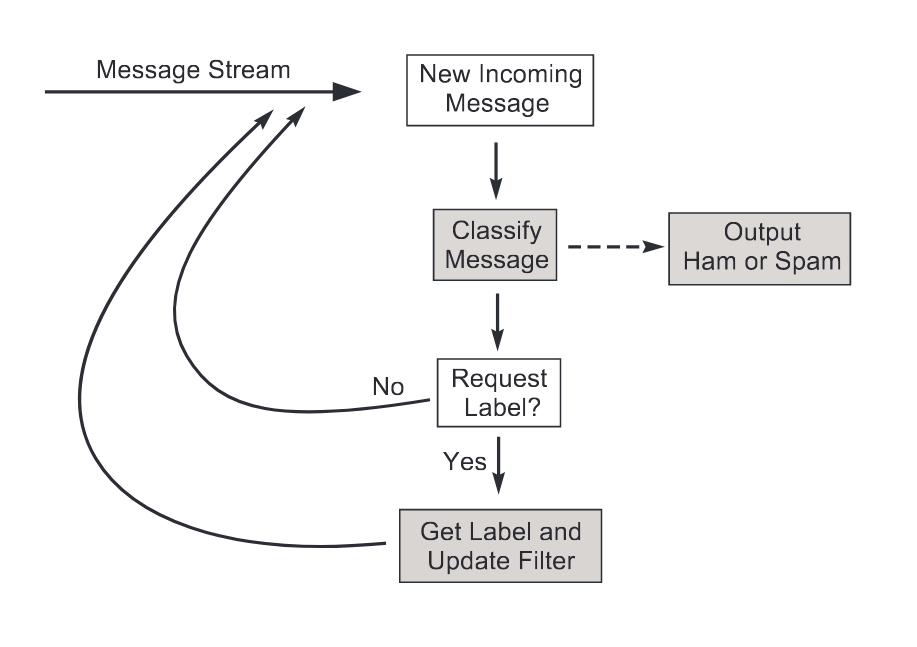
Online active learning¶
River's online active learning strategies are located in the active module. The latter contains wrapper models. These wrappers enrich the predict_one and predict_proba_one methods to include a boolean in the output.
The returned boolean indicates whether or not a label should be asked for. In a production system, we could feed this to a web interface, and get the human to annotate the sample. Offline, we can simply use the label in the dataset.
We'll implement this basic flow. We'll apply a TFIDF followed by logistic regression to a datasets of spam/ham received by SMS.
from river import active
from river import datasets
from river import feature_extraction
from river import linear_model
from river import metrics
dataset = datasets.SMSSpam()
metric = metrics.Accuracy()
model = (
feature_extraction.TFIDF(on='body') |
linear_model.LogisticRegression()
)
model = active.EntropySampler(model, seed=42)
n_samples_used = 0
for x, y in dataset:
y_pred, ask = model.predict_one(x)
metric.update(y, y_pred)
if ask:
n_samples_used += 1
model.learn_one(x, y)
metric
Downloading https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip (198.65 KB)
Uncompressing into /home/runner/river_data/SMSSpam
Accuracy: 86.60%
The performance is reasonable, even though all the dataset wasn't used for training. We can check how many samples were actually used.
print(f"{n_samples_used} / {dataset.n_samples} = {n_samples_used / dataset.n_samples:.2%}")
1922 / 5574 = 34.48%
Note that the above logic can be succinctly reproduced with the progressive_val_score function from the evaluate module. It recognises when an active learning model is provided, and will automatically display the number of samples used.
from river import evaluate
evaluate.progressive_val_score(
dataset=dataset,
model=model.clone(),
metric=metric.clone(),
print_every=1000
)
[1,000] Accuracy: 86.32% – 661 samples used
[2,000] Accuracy: 86.44% – 1,057 samples used
[3,000] Accuracy: 86.52% – 1,339 samples used
[4,000] Accuracy: 86.62% – 1,569 samples used
[5,000] Accuracy: 86.57% – 1,791 samples used
[5,574] Accuracy: 86.60% – 1,922 samples used
Accuracy: 86.60%
Reduce training time¶
Active learning is primarly used to label data in an efficient manner. However, in an online setting, active learning can also be used simply to speed up training. The point is that you can achieve a very good performance without training on an entire dataset. Active learning is a powerful way to decide which samples to train on.
¶
Production considerations¶
In production, you might want to deploy a system where humans may annotate samples queried by an active learning strategy. You have several options at your disposal, all of which go beyond the scope of River.
The general idea is to have some kind of queue in which queried samples are fed into. Then you would have a user interface which displays the elements in the queue one-by-one. Each time a sample is labeled, the label would be used to update the model. You might have one or more threads/processes doing inference. You'll want to update the model in each one each time the model learns.